Using Map-Reduce in a MongoDB Based Application
Published on
Recently I've been working on a couple of sites on-and-off in my spare time which both have a couple of things in common: they both use MongoDB as a data store and both incorporate the concept of tagging. Using MongoDB's map-reduce functionality is ideal for getting the list of tags, but it does come with its own set of potential issues which are well worth bearing in mind.
First Solution
At the most basic level the site consists of a list of posts, each with an array of tags. The application itself is a Rails 3 site using Mongoid for talking to MongoDB. The post model looks a little like the following (some stuff removed for clarity).
class Post
include Mongoid::Document
field :title
field :description
field :tags, :type => Array
end
The obvious solution is to just run a nice map-reduce command against the posts collection which will pull out the list of all the tags used across all the posts, along with the number of posts on which they have been used. To that end, I added a new method to the Post class which does the map-reduce and returns the results.
def self.all_tags()
tags = Post.collection.map_reduce(
"function() { this.tags.forEach(function(t){ emit(t, 1); }); }",
"function(key,values) { var count = 0; values.forEach(function(v){ count += v; }); return count; }"
)
opts = { :sort => ["_id", :desc] }
tags.find({}, opts).to_a \
.map!{|item| { :name => item['_id'], :post_count => item['value'].to_i } }
end
This works fine, but there are a few issues with it:
- The map-reduce is run every time the page is hit. Since a variation of this method is used to provide a list of common tags for the home page of the site, this is definitely less than ideal.
- When a map-reduce function is run in MongoDB, by default the results are stored in a temporary collection which is cleaned up once the connection to MongoDB is closed, or when it is explicitly dropped – which I am not doing. Like the above issue, having to explicitly delete the collection on every page hit seems like excessive work. However leaving it as I currently am causes all these temporary collections to build up whilst the site is running. What a waste of space.
The combination of the above problems just made me feel like something is wrong. This needed some re-thinking to make it a bit more efficient. As if the above problems weren't bad enough, it needs to be remembered that the map-reduce operation is only going to take longer over time as the site grows. What I have created with the above solution works, but is inherently an unscalable approach.
Using a Permanent Map-Reduce Results Collection
The solution to the proliferation of all the temporary result collections would seem to be using a permanent collection instead. Thankfully, this is something which MongoDB makes really easy; just pass an "out" parameter to the map-reduce call and it'll output the results to that collection make and make it permanent. MongoDB serves up another little dollop of awesome too:
Even when a permanent collection name is specified, a temporary collection name will be used during processing. At map/reduce completion, the temporary collection will be renamed to the permanent name atomically. Thus, one can perform a map/reduce job periodically with the same target collection name without worrying about a temporary state of incomplete data.
Awesome! So we can output to the same collection time and have no worries about what state it might end up in when it is queried. To implement this, we can just add the new parameter to the map-reduce call in the options hash as the API docs tell us:
tags = Post.collection.map_reduce(
"function() { this.tags.forEach(function(t){ emit(t, 1); }); }",
"function(key,values) { var count = 0; values.forEach(function(v){ count += v; }); return count; }",
{ :out => 'tags' }
)
Job done on that part. The second of our two problems has now been fixed, as we no longer have loads of temporary collections building up over time and never being cleaned up. Every time the map-reduce is run, the results are saved over the top of the 'tags' collection.
No More Map-Reduce Per Request...!
The other issue with the current system is (in my opinion) a little more important, as it is essentially a scalability-killer. MongoDB is very fast, but I don't think that's really an excuse for taking liberties with it, especially as it is obvious that this could turn into a problem when the site grows, both in terms of more visitors hitting the site and more posts (with their tags) being added.
Essentially when it comes down to it, our tag data is just a dataset which is derived from the posts collection. To that end, it only ever really needs to be rebuilt when the posts collection is changed.
To my mind, it seems the ideal solution is to split the problem out into two separate flows. The diagram below illustrates what we currently have, and what I think the aim ought to be.
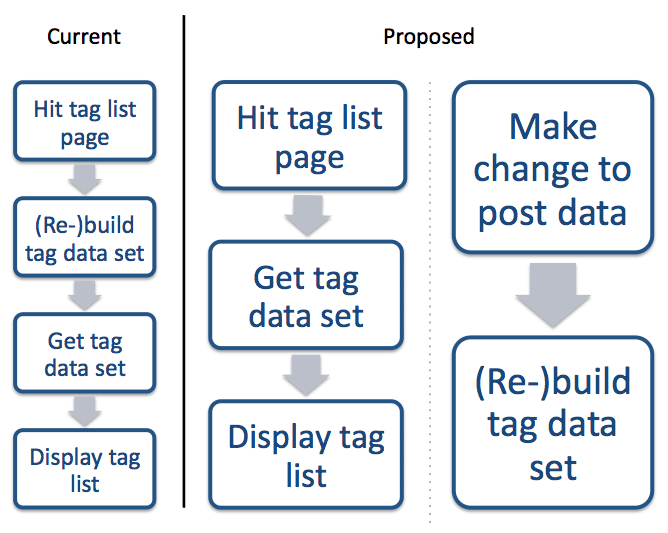
In order to achieve behaviour like this, the first step is to take the map-reduce operation out and hook up a callback for the Post class which is fired after a save. This seems to be the most appropriate, because we want to make sure we rebuild the tag data after the post collection has been changed, and we want to do this on both saving of a new post and editing of an existing one (in case the tags were changed).
The post class now looks like this:
class Post
include Mongoid::Document
field :title
field :description
field :tags, :type => Array
after_save :rebuild_tags
protected
def rebuild_tags
Post.collection.map_reduce(
"function() { this.tags.forEach(function(t){ emit(t, 1); }); }",
"function(key,values) { var count = 0; values.forEach(function(v){ count += v; }); return count; }",
{ :out => 'tags' }
)
end
end
That's all well and good, as we've pushed all the building of the tags data set out into the callback so it's only executed when a post is changed. However we've left ourselves with no way of querying them anymore. To fix this, we can just stick our all_tags method back in, but this time make sure we query the tags collection rather than running the map-reduce operation again.
def self.all_tags(limit = nil)
tags = Mongoid.master.collection('tags')
opts = { :sort => ["_id", :desc] }
opts[:limit] = limit unless limit.nil?
tags.find({}, opts).to_a \
.map!{|item| { :name => item['_id'], :post_count => item['value'].to_i } }
end
Now all of the previous functionality is once again present, with none of the disadvantages. It could be that if the site gets big enough, the rebuilding of the tags collection might be a bit much to do on every save but I doubt that will be a problem for some time. Since writes will be quite infrequent compared to reads, I'm happy with the tradeoff for the time being at least. That said, now that we've split it up like this, there is no reason we couldn't move the actual rebuilding of the tag data out entirely – into some kind of background-processing message queue perhaps – which is triggered via the after_save callback. Certainly it provides us with plenty of scope for future scalability in that department, and it wouldn't matter if the tags collection wasn't instantly updated.
Closing Thoughts
We've covered a fair bit here and it highlights the sort of consideration which heavy use of map-reduce might require. That said, all of the changes which have been made are all really straightforward and easy to make and haven't required any changes at all outside the Post class. For that, we've managed to create something which ought to hold up pretty well in terms of scalability, particularly when combined with MongoDB's own scalability in the form of sharding. Chances are it's something which these small sites will never have to worry about, but it's nice to know that it ought to be able to handle it. I think it proves how much awesome is oozing from MongoDB when used in the right place.
You may have noticed that I've kept all my tag-related logic inside my Post class. Yes, I know. Since I'ver only got a couple of fairly short methods, I'm not too worried about it, and tags are at least related to posts. However there would be no reason at all why the tag-related stuff couldn't be pulled out and put into a Tag class, in a couple of class methods. Certainly if I were going to have more methods for retrieving subsets of the data, I would do that (and may actually go ahead and do so).
Just as a closing thought, it is worth noting that for this app I am using Ruby, Rails 3 and Mongoid, but there is nothing in this post which isn't able to be done in any other environment, using the MongoDB driver of your choice.